
Throughout my software development career, I’ve seen my fair share of debates over how databases should be developed. And like most disagreements over technical pedantry, the participants are generally well-intentioned but grossly inexperienced. So much so that it wouldn’t matter if they use foreign keys or not. Though “elegant”, their software will become an unmaintainable mess after a few short years. But regardless, one counter-argument that constantly rears its ugly head goes something like, “but what if we have to change it later?”
In other debates, that question can be quickly rebutted with “uh, we just change it then,” but when the discussion is on databases, it actually holds water. It’s as if the database is a marble statue that, once shipped to production, should never be changed... and if it must, there had better be a damn good reason.
Let’s keep in mind that the whole point of developing software – that is, spending large sums of money paying developers’ salaries to build and maintain applications – is to have something that can change according to business need. When developers are unable, afraid, or unwilling to change the applications they develop, they make a very compelling case for being replaced by SAP.
Databases are Different
Databases are indeed different, especially when juxtaposed with what application developers are most familiar with: application code.
Generally speaking, application code lives in a source control system and is a set of instructions that tell that tell the machine to do something. Whether it’s compiled or interpreted, or executed on a real or virtual machine, application code does stuff.
As a developer, when you’re satisfied that it’s doing the right stuff, the release management process kicks in to promote that code through acceptance testing, quality testing, other testing, and finally production. And all along the way, the code should not change. If a bug is found, then it’s fixed in source control and sent right back through the same process.
Databases, on the other hand, live on the production database server. There can certainly be other instances – development, testing, staging – but the only one that really matters is production. And these databases don’t actually do stuff, they’re merely modified and queried by other applications with a Structured Query Language. And unlike application code, databases (or at least, their completely integrated data) do change after deployment – that’s kind of their whole point.
Database Changes Done Wrong
Unlike application code, you can’t exactly drop a bunch of files in a folder and proclaim that a new version has been successfully deployed. You also can’t just put back an older set of files to rollback your changes.
The only way to change a database is by running a SQL script against that database, and once you’ve done that, there’s no going back. You can run another SQL script to change the database again, but the only way to truly rollback changes is by restoring the entire database from back-up.
Quite a many developers struggle with this unique change process across multiple environments. I’ve heard some go so far as to say that databases are fundamentally broken, as if gravity is to blame for their inability to fly. But most developers’ reluctance to master this method leads towards a tendency to simultaneously resist change and change things uncontrollably.
If those seem contradictory, consider the Entity-Attribute-Value design. It’s one of the worst database development anti-patterns out there, and sadly one that I keep seeing happening in the wild because “what if we have to change it later.”
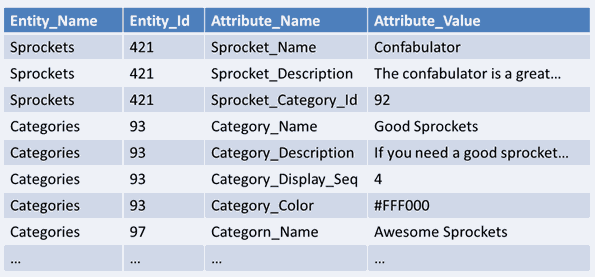
An EAV design is a shining example of the Inner-Platform Effect.
The inner-platform effect is the tendency of software architects to create a system so customizable as to become a replica, and often a poor replica, of the software development platform they are using.
In fact, it was exactly what I used to initially describe that anti-pattern. For the record, the worst anti-pattern I’ve seen took this concept once step further.
The Taxonomy of Database Scripts
As databases can really only be accessed through SQL scripts, it’s important to identify the three main categories of scripts as it relates to changes:
- Query Scripts – no impact on data or database structure, such as simple SELECT statements
- Object Scripts – alter the database, but only by adding/updating/deleting non-data objects like stored procedures, views, functions, etc.
- Change Scripts –change the structure of or the data stored within tables (ALTER TABLE, INSERT, CREATE INDEX, etc)
The first category of scripts fall out of the realm of database changes, which means that we need to concern ourselves with only two types of scripts: Object Scripts and Change Scripts.
Object Script Changes Done Right
Many applications rely on SQL scripts stored within the database – stored procedures, views, triggers, etc. – for queries they make to the database. These objects are effectively code that your application depends on, and since they’re code, they should be treated just like code. That means they “live” in source control, get labeled when your application code is built, deployed with your application code, the whole nine yards.
Doing this is surprisingly easy, and starts by creating an object script for each and every object. Each script should do three things:
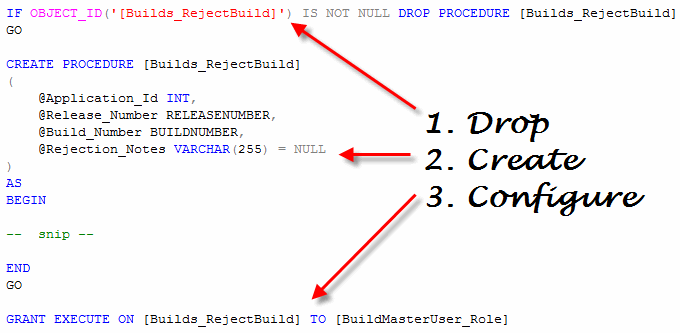
Since these object scripts simply create objects, they can be run time and time again without any real consequences. Plenty of tools are available to help extract and create these scripts for you, and once you have everything on disk, it’s just a matter of dropping it into source control.
Note how I’ve got a prefix before each script. That’s the simplest way to ensure scripts run in the correct order, as all you need is a very simple batch command script to iterate over the files in your source tree.
FOR /R . %%f IN (*.sql) DO ( OSQL -E -i "%%f" -n -b -d MyDataBase )
With this technique, your object change scripts can – and should – follow the exact same process that your application code does. After all, it’s just another code layer in the overall application.
Database Change Scripts Done Right
The thing that makes Database Change Scripts so difficult to work with is that changes are coming from two different directions. Data changes (INSERT, UPDATE, DELETE) are constantly happening in production through the day-to-day use of the application, while data structure changes (ALTER TABLE, etc.) are simultaneously occurring in development and testing environments.

Changes in both directions are an absolute requirement: application data must flow directly in to production and development changes must flow through a testing process before going to production. Shortcutting the process leads you right back to the anti-patterns we discussed: resisting change and/or uncontrollable change. But before we look at how to do it right, let’s consider some fundamentals that apply to any database change script, regardless of the database platform or scope of change.
The Cardinal Rules of Database Change Scripts
- Run once and only once – simply put, you can’t add the same column to the same table twice; while you could certainly wrap your change script in a big IF block (discussed later), that doesn’t count as running it twice
- Impossible to be “un-run” – once you’ve dropped that column, it’s gone forever; you could certainly restore your database from back-up, but that’s not exactly an undo, especially when you lose all the intermediate data
There is no getting around these rules. Period. Changes must flow in both directions, and any solution you engineer to try to work-around this fundamental will lead straight back to the aforementioned anti-patterns: resisting change and/or uncontrollable change.
Anti-pattern: Re-executable Change Scripts
One attempt to circumvent Cardinal Rule #1 is something called the re-executable change script. The idea is to surround a change script in IF block that tests whether the enclosed change script has already been run. It looks something like this:
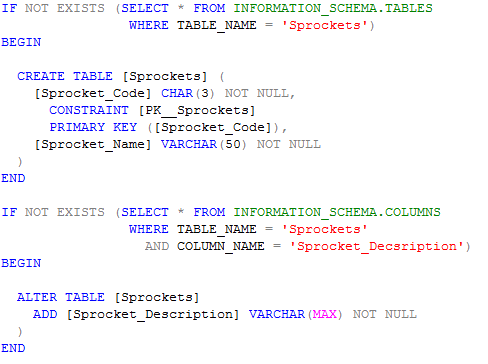
At first glance, it seems like a relatively sane way of developing change scripts. Just batch these like object scripts, and you can run them over and over and over again. A lot of developers – including many of you – swear by this technique and have had little (if any) problems using it. But like all cardinal rules violations, it leads to one of those two anti-patterns, and in this case, it’s uncontrolled changes.
In the Sprockets example above, the script is testing for the non-existence of a table named Sprockets table before running the change script. But what if a previous version of the script defined Sprocket_Name as VARCHAR(50) NULL, and that version was run and tested in QA? Multiply that by a dozen other changes in a handful of environments, and the consequences of uncontrolled change quickly become costly and difficult to pinpoint problems. Of course, you could make your testing logic more and more complex by testing each and every conceivable aspect of a table, and then ensuring that the change script would alter or create it in that precise way… but then you’d be falling into yet another anti-pattern.
Anti-pattern: Database Syncing
There are dozens and dozens of commercial and open-source “database diff” tools that will programmatically inspect the metadata of two different databases and provide a comparison of what’s different. Many of these tools will take it a step further by generating and then executing a change script to “sync” the two databases. Like re-executable change scripts, many developers swear by these tools and herald them as an end to worrying about database changes. And just like re-executable change scripts, they shortcut the cardinal rules and lead to uncontrolled changes.
The biggest sin in syncing is that, by its very nature, the process does not allow for the same change script to be tested in each environment. In each release lifecycle, each and every build is promoted to the first environment; many builds are promoted to other pre-production environments; and just one build is promoted to production. As database changes are intricately tied with application code changes, database synchronizations occur in a similar fashion to builds.
This funnel is perfectly fine for application code. After all, you’re just replacing an entire set of files with an entire set of new files; the operating system doesn’t care what new functions or classes have been added to the code. But the database sync process not only needs to understand exactly what changed, but generate and then execute a change script. Compared to application code, that’d be like using Reflector (or any other disassembler) to diff functionality and then deploy those diffs while the application is running.
To make matters worse, the generated change scripts will be different between each environment because they represent a different set of changes. Worse still, the last and final sync to Production is an amalgam of all syncs before it, making it the riskiest and most uncontrolled change of them all.
Following the Cardinal Rules
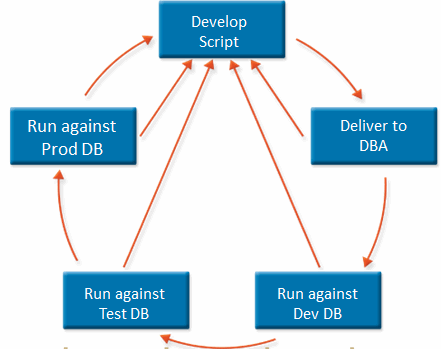
Since you can’t work your way around the Cardinal Rules, you may as well develop a process to work with them.
- Develop a Change Script – use any tool you’d like, so long as the output is a SQL script; the more human readable, the better, especially if you want to get in to the next step
- (Optional) Code Review – this is optional, of course, but it’s always nice to have a second set of eyes
- Execute Script in Test Environment(s) – run the exact same script in each environment as you deploy your application code
- Execute Script in Production – by this point, you should be pretty confident that a script that’s been run several times before should run fine when it counts
ON FAIL, FIX DATABASES AND GO TO 1 – this is perhaps the most important part of the process; if something goes wrong in test, fix the database (restore from backup ideally) and the databases before it, figure out why it failed, write a new script, and start from the beginning; every environment you don’t run the new script in is one less test before production
Tools of the Trade
A process is only as good as how it’s implemented, and with database change scripts, there are three important tools needed to implement the process.
Change Script Library
All the change scripts that you write will have to live somewhere, and their home should be a special place. In addition to storing the script itself, the change script library should have:
- Write-Once – change scripts cannot change throughout the release lifecycle; they are not changed, they are undone (ideally, through a restore) and discarded
- Metadata – in addition to the change script itself, the following attributes are important to track
- Unique ID (at least, unique within the application)
- Author
- Target Application
- Target Release Number
- Controlled/Auditable Access – ensuring not only that authorized developers maintain change scripts, but that they follow the aforementioned rules
Neither file systems nor source control systems meet all of these requirements, but they can work with the aid of a spreadsheet and some well-disciplined developers. There are also some tools specifically designed to solve this problem, including the product I work on (BuildMaster) at the day job (Inedo).
Execution Logs
Database change scripts will end up being executed multiple times, and knowing the specifics of these executions is as important as knowing who changed which sourcefiles. At a minimum, an execution log should be maintained in production, but it certainly can be helpful to know which scripts were run in which order in the lower environments. The execution log should track the following:
- Script Unique ID
- Who executed the script
- When it was executed
- Database it was executed against
- Status of the execution (Fail or Success)
- Script output log
Database Versioning
Whereas the Execution Log is an external indicator of which change scripts have been executed against which database, a database versioning system allows the database itself to have a history of its own changes. Database versioning is as simple as maintaining a metadata table with two columns: Unique ID and Execution Date. Before executing a change script, simply check the table to see if the script has been executed already and, if not, run it and stored the script’s unique ID and date.
Having a metadata table allows you to easily revert to a back-up of the database and re-run any change scripts that need to be executed. This is particularly useful for restoring the production database in pre-production environments. Maintaining a versioning table isn’t too difficult of a process to automate, and I’ve certainly written my share of scripts to do this over the years. Including the change script management feature within BuildMaster:
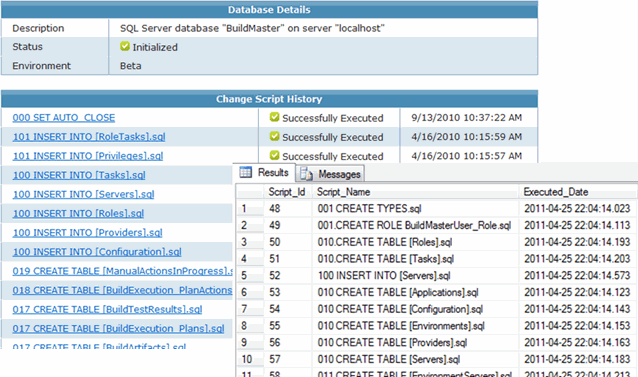
Another great benefit to database versioning (and a change script library) is the ability spin up a new database environment – including developers’ workstations – with minimal hassle, even if it’s months or years after the system has been live.
Wrapping Things Up
Database are not just at the center of your applications, but they are the center. Application data will outlive application code by many lifetimes, especially as we become more and more reliant and software and become accustomed to, say, look at what orders we placed just a “few years” ago on Amazon.
If you’re afraid of making database changes, or you make so many reckless changes that you’re shamed into never touching a database again, then your legacy will become creating legacy applications that no one wants to — nor can reasonably — maintain.